Capture Real Voices, Label Them Right, Ship Smarter AI
By Humyn Labs | AI Training Data and Voice Datasets | Updated June 2026
| TL;DR Your AI hears the world through the data you give it. Weak voice data collection hands it noise. Sloppy labeling teaches it the wrong habits. Humyn Labs runs both inside one AI data annotation platform, so you capture real human speech from verified speakers across 50+ languages, label it under multi-layer QC, and ship models that understand people. Share your spec and get a collection plan plus sample recordings inside 48 hours. |
What is voice data collection and AI data annotation?
| Voice data collection captures real human speech under controlled conditions. AI data annotation labels that audio so machines can learn from it. Humyn Labs runs both on one platform. You walk away with clean, accurately labeled voice datasets that raise model accuracy and shorten your path to launch. |
Picture this. Your voice assistant nails the demo. Then a real customer calls. She speaks with a thick Rajasthani accent. A fan hums behind her. A kid yells somewhere down the hall. Your model drops one word in five and sends her to the wrong department. She hangs up. That breakdown did not begin in your code. It began in your data.
Most voice AI fails for one dull reason. The speech it trained on never sounded like real life. And even teams that capture decent audio often slap weak labels underneath it. Two halves of one job. Most teams nail neither. That gap is exactly where a real voice data collection and ai data annotation platform pays for itself. Humyn Labs built one platform for both, so the speech you capture and the labels you add stay accurate from the first take to the final handoff.
Here is what you will learn, and how Humyn Labs fixes each problem you are probably hitting right now.
Why most voice AI breaks before it ships
Garbage in, garbage out is tired advice. It still rules voice AI in 2026. The speech and voice recognition market is set to hit 23.7 billion dollars in 2026 and climb past 104 billion by 2034, per Fortune Business Insights. Every one of those models needs real human speech to learn from. Scraped clips and synthetic audio will not carry you there.
Three failures keep showing up.
- Thin diversity. Public sets like LibriSpeech and Common Voice lean hard toward English and clean studio reads. Your users do not talk like audiobook narrators.
- Dirty audio. Mismatched sample rates, clipping, and background noise tank accuracy in production. Teams lose months scrubbing data that still misses the speaker coverage they need.
- Lazy labels. One mislabeled second of audio looks harmless. Spread it across a million clips and your error rate swells. The model learns the wrong lesson, and learns it with confidence.
Quick gut check. Would your model survive a noisy café and a heavy accent at the same time? If you hesitated, your training data needs work. That is the problem Humyn Labs set out to fix.
What real voice data collection actually looks like
Real voice data collection means real people. Recorded on purpose. To a spec you control. Not bots. Not stock libraries. Humyn Labs sources studio-quality recordings from identity-verified speakers across more than 50 languages, with deep Indic coverage like Hindi, Tamil, Telugu, Kannada, Malayalam, and Bengali.
Coverage that matches your real users
You set the distribution. Need 500 hours of Hindi female speakers aged 25 to 35 with Rajasthani accents? You get exactly that. Age, gender, accent, dialect, and region all stay in your control, and every speaker arrives with documented demographics instead of self-reported guesses. That is the kind of speech dataset that holds firm when your model meets the public.
Quality you can defend
Every recording follows defined audio specs. Sample rate, bit depth, noise floor, and clipping all get checked. Files that fail get rejected before they reach your pipeline. Read speech, spontaneous conversation, emotional speech, wake words, multi-speaker dialogue, noisy-environment clips. The collection types mirror how your model will really get used.
Consent baked in from day one
Every speaker gives verified informed consent. Data handling follows GDPR and regional privacy rules. Your usage rights stay clear before the first session begins. No ugly licensing surprises six months into training.
See also: Understanding the Internet of Things Technology
Where the AI data annotation platform earns its keep
Raw audio is not training data. Labels make it useful. A strong ai data annotation platform turns sound into structure: transcription, speaker labeling, timestamps, intent tags, and emotion markup. Humyn Labs runs audio annotation with verified humans in the loop, not automated-only labeling that misses the nuance.
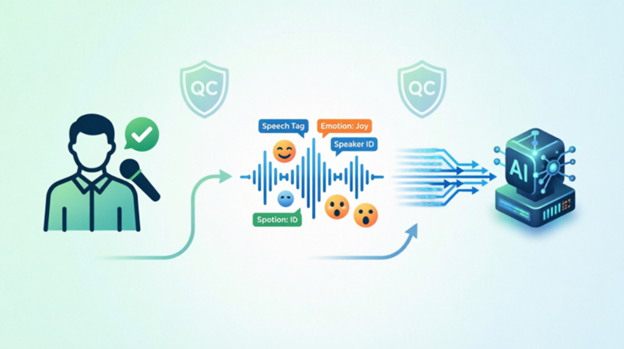
Human in the loop, explained simply
Trust comes from agreement. When two trained labelers hear the same clip and tag it the same way, you can trust that label. When they split, a reviewer settles it. That agreement check is how quality survives scale. Humyn Labs pairs peer review with a centralized QC team, so the same standard holds across a thousand hours as it does across ten. See it in action on the human in the loop page.
Speech recognition accuracy for English now tops 97 percent in low-noise settings, per Google benchmarks. That number falls fast on accents, code-switching, and noise unless your labeled data covers them. Strong annotation is what closes that gap.
One platform for both jobs: why combining them wins
Most teams bolt two vendors together. One captures audio. The other labels it. The handoff is where it cracks. Provenance, the record of where the data came from, gets murky. Timelines slip. When quality drops, both vendors point fingers and you absorb the delay.
A unified voice data collection and ai data annotation platform keeps the whole chain whole. The team that records your speech also labels it, under one QC standard, with full traceability. So how do the two paths stack up?
| What you care about | Stitched-together vendors | Humyn Labs unified pipeline |
| Accountability | Two vendors, finger-pointing | One team owns the result |
| Data provenance | Lost in the handoff | Tracked end to end, onchain reputation |
| Speed | Slowed by coordination | Milestone delivery, early batches |
| Quality control | Two standards, gaps between | Single multi-layer QC standard |
| Total cost | Hidden cleanup and rework | Lower rework, faster to train |
Real example. A healthcare voice-AI team needed Hindi and Tamil clinical speech with emotion tags for a patient triage assistant. Sourcing and labeling in one place cut their retraining loops. The labelers knew the medical context, so the tags landed right the first time. That is the payoff of keeping both jobs under one roof.
The business payoff: what you actually gain

So what does better data actually buy you? This is the part your CFO cares about. Better data is not a vanity spend. It moves real numbers.
- Higher accuracy out of the gate. Diverse, well-labeled speech means fewer retraining loops and less wasted compute.
- Faster time to launch. Milestone delivery lets you train on early batches instead of waiting for the full set.
- Models that handle the real world. Accent and noise coverage protects user trust, which protects adoption.
- De-risked compliance. Verified consent and clear usage rights keep enterprise and regulated use cases clean.
| Proof point. Companies using voice AI report a three-year ROI between 331 and 391 percent, per a Forrester study. Production voice agent deployments jumped 340 percent year over year across 500-plus organizations. The teams winning that race train on cleaner, more diverse voice data. Not luck. Better inputs. |
How to start with Humyn Labs
Starting is simple. Four steps, one team.
- Scope your use case. Tell us your languages, accents, demographics, audio format, and accuracy targets.
- Get a collection plan. Humyn Labs builds the recording spec around your real deployment conditions, not a generic template.
- Record and annotate. Verified speakers record to spec. Audio passes QC. Annotation runs with human review at every layer.
- Receive training-ready data. Delivered in your format with full metadata. Sample recordings and a plan land within 48 hours of your brief.
Want to see the full workflow first? Walk through how it works, or just talk to the team and scope your dataset.
Common mistakes to avoid
- Leaning on public datasets. They skew English, lack diversity, and carry restrictive licensing. Production voice AI needs custom data.
- Treating annotation as an afterthought. Labels are not a checkbox. They are half of what your model learns from.
- Skipping consent and provenance. Unverified speaker metadata and murky licensing turn into legal headaches later.
- Splitting collection and labeling across vendors. The handoff is where quality and timelines die.
Capture, label, ship
Your AI is only as smart as the voices it learns from and the labels you stack on top of them. That is the whole game. Capture real speech from real people. Label it right with humans who grasp the context. Ship a model that truly understands your users.
Your competitors already train on cleaner, more diverse voice data. Every week you spend scrubbing noisy clips is a week your model slips behind. Humyn Labs runs both jobs in one place, so you stop fighting your data and start trusting it. Scope your voice dataset with Humyn Labs and get your plan in 48 hours.
Frequently asked questions
What is the difference between voice data collection and AI data annotation?
Voice data collection captures new speech audio from human speakers. AI data annotation labels existing audio with transcriptions, speaker tags, timestamps, and emotion markers. Humyn Labs delivers both in a single pipeline, so your data stays consistent from capture through label.
Why use one platform for both instead of separate vendors?
Separate vendors create a handoff gap where provenance, quality, and timelines slip. A unified voice data collection and AI data annotation platform keeps one team accountable end to end, with a single QC standard and full traceability.
How does annotation quality affect voice AI accuracy?
Labels are what your model learns from. A small labeling error repeated across millions of clips inflates your error rate. Human-in-the-loop review and labeler agreement keep labels accurate at scale, which lifts model accuracy directly.
What languages and accents can Humyn Labs collect and label?
Humyn Labs covers 50+ languages with deep Indic support including Hindi, Tamil, Telugu, Kannada, Malayalam, and Bengali. Native speakers verify dialect and accent coverage within each language, and you control the demographic distribution.
How fast can I get a labeled voice dataset?
You receive a collection plan and sample recordings within 48 hours of sharing your spec. A pilot of 50 to 100 hours usually runs two to four weeks. Large multilingual collections ship in milestones so you can train on early batches.
Why not just use public speech datasets?
Public sets like LibriSpeech and Common Voice skew toward English, lack demographic diversity, vary in quality, and carry restrictive licensing. Custom collection matched to your language, accent, and quality needs gives production-grade results.